
Полезны ли ссылки закрытые от индексации

Каким бы продуманным не был сайт, он всегда будет иметь страницы, нежелательные для индексации. Обработка таких документов поисковыми роботами снижает эффект SEO-оптимизации и может ухудшать позиции сайта в выдаче. В профессиональном лексиконе оптимизаторов за такими страницами закрепилось название «мусорные». На наш взгляд этот термин не совсем корректный, и вносит путаницу в понимание ситуации.
Мусорными страницами уместнее называть документы, не представляющие ценности ни для пользователей, ни для поисковых систем. Когда речь идет о таком контенте, нет смысла утруждаться с закрытием, поскольку его всегда легче просто удалить. Но часто ситуация не столь однозначна: страница может быть полезной с т.з. пользовательского опыта и в то же время нежелательной для индексации. Называть подобный документ «мусорным» — неправильно.
Такое бывает, например, когда разные по содержанию страницы создают для поисковиков иллюзию дублированного контента. Попав в индекс такой «псевдодубль» может привести к сложностям с ранжированием. Также некоторые страницы закрывают от индексации с целью рационализации краулингового бюджета. Количество документов, которые поисковики способны просканировать на сайте, ограниченно определенным лимитом. Чтобы ресурсы краулеров тратились исключительно на важный контент, и он быстрее попадал в индекс, устанавливают запрет на обход неприоритетных страниц.
Как закрыть страницы от индексации: три базовых способа
Добавление метатега Robots
Наличие атрибута noindex в html-коде документа сигнализирует поисковым системам, что страница не рекомендована к индексации, и ее необходимо изъять из результатов выдачи. В начале html-документа в блоке <head> прописывают метатег:
Эта директива воспринимается краулерами обеих систем — страница будет исключена из поиска как в Google, так и в «Яндексе» даже если на нее проставлены ссылки с других документов.
Варианты использования метатега Robots
Закрытие в robots.txt
Закрыть от индексации отдельные страницы или полностью весь сайт (когда это нужно — мы поговорим ниже) можно через служебный файл robots.txt. Прописав в нем одну из директив, поисковым системам будет задан рекомендуемый формат индексации сайта. Вот несколько основных примеров использования robots.txt
Запрет индексирования сайта всеми поисковыми системами:
User-agent: *
Disallow: /
Закрытие обхода для одного поисковика (в нашем случае «Яндекса»):
User-agent: Yandex
Disallow: /
Запрет индексации сайта всеми поисковыми системами, кроме одной:
User-agent: *
Disallow: /
User-agent: Yandex
Allow: /
Закрытие от индексации конкретной страницы:
User-agent: *
Disallow: / #частичный или полный URL закрываемой страницы
Отдельно отметим, что закрытие страниц через метатег Robots и файл robots.txt — это лишь рекомендации для поисковых систем. Оба этих способа не дают стопроцентных гарантий, что указанные документы не будут отправлены в индекс.
Настройка HTTP-заголовка X-Robots-Tag
Указать поисковикам условия индексирования конкретных страниц можно через настройку HTTP-заголовка X-Robots-Tag для определенного URL на сервере вашего сайта.
Заголовок X-Robots-Tag запрещает индексирование страницы
Что убирать из индекса?
Рассмотрев три основных способа настройки индексации, теперь поговорим о том, что конкретно нужно закрывать, чтобы оптимизировать краулинг сайта.
Документы PDF, DOC, XLS
На многих сайтах помимо основного контента присутствуют файлы с расширением PDF, DOC, XLS. Как правило, это всевозможные договора, инструкции, прайс-листы и другие документы, представляющие потенциальную ценность для пользователя, но в то же время способные размывать релевантность страницы из-за попадания в индекс большого объема второстепенного контента. В некоторых случаях такой документ может ранжироваться лучше основной страницы, занимая в поиске более высокие позиции. Именно поэтому все объекты с расширением PDF, DOC, XLS целесообразно убирать из индекса. Удобнее всего это делать в robots.txt.
Страницы с версиями для печати
Страницы с текстом, отформатированным под печать — еще один полезный пользовательский атрибут, который в то же время не всегда однозначно воспринимается поисковиками. Такие документы часто распознаются краулерами как дублированный контент, оказывая негативный эффект для продвижения. Он может выражаться во взаимном ослаблении позиций страниц и нежелательном перераспределении ссылочного веса с основного документа на второстепенный. Иногда поисковые алгоритмы считают такие дубли более релевантными, и вместо основной страницы в выдаче отображают версию для печати, поэтому их уместно закрывать от индексации.
Страницы пагинации
Нужно ли закрывать от роботов страницы пагинации? Данный вопрос становится камнем преткновения для многих оптимизаторов в первую очередь из-за диаметрально противоположных мнений на этот счет. Постраничный вывод контента на страницах листинга однозначно нужен, поскольку это важный элемент внутренней оптимизации. Но в необработанном состоянии страницы пагинации могут восприниматься как дублированный контент со всеми вытекающими последствиями для ранжирования.
Первый подход к решению этой проблемы — настройка метатега Robots. С помощью noindex, follow из индекса исключают все страницы пагинации кроме первой, но не запрещают краулерам переходить по ссылкам внутри них. Второй вариант обработки не предусматривает закрытия страниц. Вместо этого настраивают атрибуты rel=”canonical”, rel=”prev” и rel=”next”. Опыт показывает, что оба этих подхода имеют право на жизнь, хотя в своей практике мы чаще используем первый вариант.
Страницы служебного пользования
Технические страницы, предназначенные для административного использования, также целесообразно закрывать от индексации. Например, это может быть форма авторизации для входа в админку или другие служебные страницы. Удобнее всего это делать через директиву в robots.txt. Документы, к которым необходимо ограничить доступ, можно указывать списком, прописывая каждый с новой строки.
Директива в robots.txt на запрет индексации всеми поисковиками нескольких страниц
Формы и элементы для зарегистрированных пользователей
Речь идет об элементах, которые ориентированы на уже существующих клиентов, но не представляют ценности для остальных пользователей. К ним относят: страницы регистрации, формы заявок, корзину, личный кабинет и т.д. Индексацию таких элементов целесообразно ограничить как минимум из соображений оптимизации краулингового бюджета. На сайтах электронной коммерции отдельное внимание уделяют закрытию страниц, содержащих персональные данные клиентов.
Закрытие сайта во время технических работ
Создавая сайт с нуля или проводя его глобальную реорганизацию, например перенося на новую CMS, желательно разворачивать проект на тестовом сервере и закрывать его от сканирования всеми поисковыми системами в robots.txt. Это уменьшит риск попадания в индекс ненужных документов и другого тестового мусора, который в дальнейшем сможет навредить поисковому продвижению сайта.
Заключение
Настройка индексирования отдельных страниц — важный компонент поисковой оптимизации. Вне зависимости от технических особенностей каждый сайт имеет документы, нежелательные для попадания в индекс. Какой контент лучше скрывать от роботов и как это делать в каждом конкретном случае — мы подробно рассказали выше. Придерживаясь этих рекомендаций, вы оптимизируете ресурсы поисковых краулеров, обеспечите быстрые и эффективные обходы приоритетных страниц, и что самое важное — обезопаситесь от возможных проблем с ранжированием.
Читайте по теме:
Как оптимизировать страницы категорий онлайн-магазинов?
SEO-оптимизация главной страницы интернет-магазина. Подробное руководство
Источник
![]()
E-books New
Кейсы
SEO
Вебинары
Новости
How-to
Контент-маркетинг
PPC
Аналитика
Маркетинг
Serpstat использует файлы cookie для обеспечения работоспособности сервиса, улучшения навигации, предоставления возможности связаться с командой поддержки, а также маркетинговых активностей Serpstat.
Нажав кнопку «Принять и продолжить», вы соглашаетесь с Политикой конфиденциальности
// В этом файле есть те нужные стили которые в других файлах нет.?>
10841
2
| How-to | – Читать 8 минут – | 30 января 2019 |

ЧЕК-ЛИСТ: ТЕХНИЧЕСКАЯ ЧАСТЬ — ИСПРАВЛЕНИЕ
Контент сайта должен быть информативным и полезным для пользователя, а соответствующие страницы — открытыми для сканирования поисковым роботом. Однако есть случаи, когда индексация страницы нежелательна и может уменьшить эффект от оптимизации.
Причины ограничить индексацию страниц
Владелец сайта заинтересован, чтобы потенциальный клиент находил его веб-ресурс в выдаче, а поисковая система — в том, чтобы предоставить пользователю ценную и релевантную информацию. Для индексации должны быть открыты только те страницы, которые имеет смысл выводить в результаты поиска.
Рассмотрим причины, по которым следует запретить индексацию сайта или отдельных страниц:
Контент не несет в себе смысловой нагрузки для поисковой системы и пользователей или же вводит их в заблуждение.
К такому контенту можно отнести технические и административные страницы сайта, данные с персональной информацией. Также некоторые страницы могут создать иллюзию дублированного контента, что является нарушением и может привести к штрафным санкциям для всего ресурса.
Нерациональное использование краулингового бюджета.
Краулинговый бюджет — это определенное количество страниц сайта, которое может просканировать поисковая система. В наших интересах тратить ресурсы сервера только на ценные и качественные страницы. Чтобы получить быструю и результативную индексацию важного содержимого веб-ресурса, необходимо закрыть от сканирования ненужный контент.
Чтобы проверить, какие страницы вашего сайта сейчас находятся в топе поисковой выдаче, и по каким фразам их находят — воспользуйтесь Serpstat.
Какие страницы лучше убрать из индекса
Страницы сайта в процессе разработки
Если проект только в процессе создания, лучше закрыть сайт от поисковиков. Рекомендуется открыть доступ к сканированию наполненных и оптимизированных страниц, отображение которых в результатах поиска целесообразно. При разработке сайта на тестовом сервере доступ к нему должен быть ограничен с помощью файла robots.txt, no index или пароля.
Настраивая копию сайта, важно правильно указать зеркало с помощью 301 редиректов, либо атрибута rel= «canonical», чтобы сохранить рейтинг существующего ресурса и проинформировать поисковую систему: где сайт-первоисточник, а где его аналог. Закрывать от индексации работающий ресурс крайне нежелательно. Тем самым можно обнулить возраст сайта и наработанную репутацию.
Страницы печати могут быть полезны посетителю. Нужную информацию можно распечатать в виде адаптированного текста: статью, сведения о товаре, карту расположения организации.
По сути страница печати является копией её основной версии. Если эта страница открыта для индексации, поисковый робот может выбрать ее приоритетной и более релевантной. Для правильной оптимизации сайта с большим числом страниц следует установить запрет индексации страниц для печати.
Чтобы закрыть ссылку на документ, можно использовать вывод контента с помощью AJAX, закрыть страницы с помощью метатега <meta name=»robots» content=»noindex, follow»/>, либо в robots.txt закрыть от индексации все страницы печати.
На сайте, кроме страниц с основным контентом, могут присутствовать документы PDF, DOC, XLS, доступные для чтения и загрузки. В результатах поиска на ряду со страницами сайта можно увидеть заголовки pdf-файлов.
Возможно, содержимое этих файлов не отвечает запросам целевой аудитории сайта. Или же документы появляются в поиске выше html-страниц сайта. В этом случае индексация документов нежелательна, и их лучше закрыть от сканирования в файле robots.txt.

Пользовательские формы и элементы
Сюда относят все страницы, которые полезны для клиентов, но не несут информационной ценности для других пользователей и, как следствие, поисковых систем. Это могут быть формы регистрации и оформления заявок, корзина, личный кабинет. Доступ к таким страницам следует ограничить.
Технические страницы нужны исключительно для служебного использования администратором. Например, форма авторизации для входа в панель управления.
Персональная информация о клиентах
Эти данные могут содержать не только только имя и фамилию зарегистрированного пользователя, но и контактные и платежные данные, оставленные при оформлении заказа. Эта информация должна быть надежно защищена от просмотра.
Особенности структуры таких страниц делают их похожими друг на друга. Чтобы снизить риск санкций от поисковых систем за дублированный контент, рекомендуем закрывать к ним доступ.
Данные страницы хоть частично и дублируют содержание основной страницы, закрывать от индексации их не рекомендуется, для них необходимо настроить атрибут rel=»canonical», атрибуты rel=»prev» и rel=»next», указать в Google Search Console в разделе «Параметры URL», какие параметры разбивают страницы, либо целенаправленно их оптимизировать.
Как закрыть страницы от индексации
Метатег robots со значением noindex в html-файле
Наличие атрибута noindex в html-коде страницы — это сигнал поисковой системе о том, что ее следует исключить из результатов поиска. Чтобы использовать метатеги, необходимо в заголовок <head> соответствующего html-документа добавить <meta name=»robots» content=»noindex, follow»/>.
При использовании данного метода страница будет закрыта для сканирования даже при наличии внешних ссылок на нее.
Чтобы закрыть текст от индексации (или отдельный фрагмент текста), а не всю страницу, воспользуйтесь html-тегом: <noindex>текст</noindex>. Помните, что данный тег «понимает» только Яндекс: бот Google его проигнорирует.
В этом документе можно заблокировать доступ ко всем выбранным страницам или указать поисковикам не индексировать сайт.
Ограничить индексацию страниц через файл robots.txt можно так:
Disallow: /catalog/ #частичный или полный URL закрываемой страницы
Чтобы использование этого метода было эффективным, следует проверить, нет ли внешних ссылок на раздел сайта, который нужно скрыть, а также изменить все внутренние ссылки, ведущие на него.
Файл конфигурации .htaccess
Используя этот документ можно ограничить доступ к сайту с помощью пароля. Необходимо указать Username пользователей, которые смогут попасть к нужным страницам и документам, в файле паролей .htpasswd. Затем указать путь к этому файлу с помощью специального кода в файле .htaccess.
AuthName «Password Protected Area»
AuthUserFile путь к файлу с паролем
Require valid-user
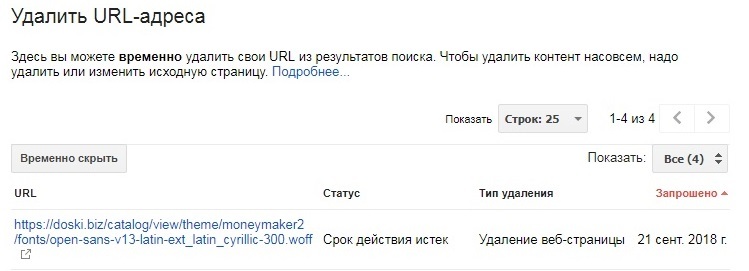
Удаление URL через сервисы веб-мастеров
Удаление URL через сервисы веб-мастеров
В Google Search Console можно убрать страницу из результатов поиска, указав URL в специальной форме и обозначив причину ее удаления. Функция удаления страниц доступна в разделе «Индекс Google». Обработка запроса может занять некоторое время.
Управление индексацией — важный этап SEO. Следует не только оптимизировать перспективные для трафика страницы, но и скрывать от индексации контент, продвижение которого не несет никакой пользы.
Ограничение доступа к ряду страниц и документов сэкономит ресурсы поисковой системы и ускорит индексацию сайта в целом.
«Список задач» — готовый to-do лист, который поможет вести учет
о выполнении работ по конкретному проекту. Инструмент содержит готовые шаблоны с обширным списком параметров по развитию проекта, к которым также можно добавлять собственные пункты.
Начать работу со «Списком задач»
Сэкономьте время на изучении Serpstat
Хотите получить персональную демонстрацию сервиса, тестовый период или эффективные кейсы использования Serpstat?
Оставьте заявку и мы свяжемся с вами 😉
Оцените статью по 5-бальной шкале
4.2 из 5 на основе 9 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Не успеваешь следить за новостями? Не беда! Наш любимый редактор Анастасия подберет материалы, которые точно помогут в работе. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Источник