
Полезные сервисы как собрать семантическое ядро

Сделал подборку из 16 сервисов для сбора и работы с семантическим ядром.
У сервиса большой инструментарий для работы с семантикой.
SemRush покажет вам, на какие ключевые слова следует обратить внимание, чтобы обойти конкурентов. Поможет узнать общие и уникальные ключевые слова доменов. Есть базы ключевых слов для 26 стран.
Всем известный сервис для анализа поисковых запросов в Яндексе. Есть возможность смотреть статистику поисковой фразы по регионам, похожие поисковые запросы и историю запросов в разрезе года.
Расширение для браузеров, которое позволяет значительно ускорить ручной сбор слов из Яндекс Wordstat. С помощью расширения вы сможете одним кликом выбрать все ключевые слова на странице и копировать в буфер обмена.
Бесплатная версия Keyword Tool генерирует до 750 + ключевых слов для каждого поискового запроса. Собирает поисковые подсказки, частотность и может анализировать домены конкурентов. Сервис позиционирует себя, как лучшая альтернатива планировщику ключевых слов Google.
Профессиональный инструмент для работы с семантическим ядром сайта. Собирает статистику поисковых запросов Google, Яндекс, Mail, поисковые подсказки Google и Яндекс и еще много всего.
Сервис умеет анализировать позиций поисковых запросов в Яндекс и Google. Парсить ключи из Яндекс Wordstat, собирать подсказки Яндекса, Google и YouTube.
Сервис, позволяющий получать информацию о рекламных кампаниях конкурентов. Работает по гео: Москва, Санкт-Петербург, Киев, Астана. Что вы сможете узнать о конкуренте: ключевые запросы, тексты объявлений, позиции, получите оценку трафика и бюджета.
8. Планировщик ключевых слов Google (в Google Ads)
Инструмент ищет и прогнозирует эффективность ключевых слов (трафик, бюджет, ctr, cpc) для рекламы в Google Ads. Найденные ключевые слова можно в один клик загрузить в рекламную кампанию Google Ads
Платформа состоящая из пяти блоков: анализ обратных ссылок, SEO-аудит сайта, анализ семантики, аналитика конкурентов, мониторинг позиций.
Быстрый сбор семантики, кластеризация запросов и выгрузка данных в csv или xlsx
Сервис быстро собирает ключи из wordstat, поисковые подсказки и частотность. Есть настройки по региону, глубине частотности, может парсить ставки Яндекс Директа.
Статистика по ключевым запросам за год. Оценка конкуренции по каждому ключевику. Еще сервис предлагает идеи ключевых слов. (интересная функция)
Сервис для парсинга поисковых запросов. Бесплатная версия сервиса сильно урезана. Есть такие инструменты как: дополняющие фразы, базы запросов, сравнение сайтов, чистка неявных дублей, доля конкурентов по фразам и т.д.
Широкий инструментарий для работы с ключевиками. (есть бесплатная версия) Сервис может: парсить ключи из Яндекс Wordstat, пересекать и склонять фразы, выделять уникальные ключи из списка и подсчитывать их. Также есть кросс-минусовка фраз, удаление дублей и поиск синонимов.
С помощью Google Trends можно проанализировать популярность поискового запроса в разрезе по городам/субрегионам. Посмотреть похожие запросы. Сравнить свою компанию с конкурентом по популярности в субрегионах. (Данные из поисковика Google)
Сервис подбора ключевых слов.
Есть простой подбор слов (поиск по одному слову) и расширенный (поиск по списку ключевых слов). В бесплатной версии можно выгружать не более 3000 ключевых слов в csv. Сервис может: искать семантическое ядро конкурентов, удалять дубликаты, собирать частотность запросов, группировать словоформы при анализе уникальных слов.
Напишите в комментарии, какими сервисами вы пользуйтесь и можете порекомендовать.
Автор телеграм-канал (@proroas), пишу о digital-маркетинге, сервисах и аналитике. О том, чем пользуюсь в работе сам.
Источник
Доброго времени суток, дорогие читатели нашего блога. На моих часах 1:10 ночи, в наушниках играет очередной подкаст Neuropunk Records, а, значит, самое время написать сочную статью.
В этот раз мы затронем вопрос семантического ядра сайта (она же СЯ, она же семантика) — что это, как собрать самостоятельно и какие программы и сервисы-помощники можно использовать. Статья направлена, в первую очередь, на молодых SEO-специалистов, маркетологов и владельцев бизнеса, которые хотят развивать свой проект в интернете самостоятельно. Опытным сеошникам я вряд ли открою какие-то новые горизонты сбора СЯ, но кто знает наверняка, а? 🙂
Прим. автора: хочется сразу сказать, что в этих ваших интернетах существует великое множество онлайн-сервисов и скачиваемых программ, которые можно тем или иным образом использовать для сбора семантического ядра. В своей статье я хочу рассказать только о самых популярных, т.к. не вижу смысла пережевывать одни и те же функции. У всех они примерно одинаковые.
Ладно, поехали.
Семантическое ядро — определение, основные правила сбора
Итак, семантическое ядро сайта — это массив всех релевантных (тематических) запросов, по которым человек может и должен найти ваш сайт в выдаче поисковых систем. Семантическое ядро должно быть разбито на группы запросов (кластеры). Каждый кластер должен иметь привязку к какой-то релевантной посадочной странице. Т.е., проще говоря, вы должны сразу определить для себя по каким запросам и на какие страницы вашего сайта должен переходить пользователь из поиска.
Оформить СЯ можно так, как вам удобнее, мне, например, привычнее делать это в стандартном excel, используя несколько столбцов: группа запросов, сами запросы, посадочная страница кластера и title кластера. Иногда еще указываю для себя частотности запросов, чтобы помнить где у меня ВЧ, СЧ и НЧ.
При сборе семантики следует придерживаться нескольких правил
- Отделяйте транзакционные запросы от информационных.
Не нужно пытаться впихнуть невпихуемое на одну страницу. Например, запрос “купить дом в Анапе” — это одна посадочная страница, а запрос “Почему в Анапе жить хорошо?” — совершенно другая (вероятнее всего статья или гайд). Можно, конечно, взять продающую страницу с предложениями недвижимости и расписать там огромную простыню текста, в котором будут подробно указаны все преимущества жизни в Анапе, но далеко не факт, что это сыграет вам на руку — либо коммерческие запросы перекроют информационные, либо, наоборот, либо ни те, ни другие не выйдут в ТОП. В общем, каждому запросу должно быть свое место. - Внимательно выбирайте посадочные страницы.
Да, в большинстве случаев и без глубокого анализа конкурентов понятно, какой запрос, на какую страницу должен вести. Однако случается и такое, что очевидное ключевое слово на деле у 80% ТОП-конкурентов ведет не туда, куда вы планировали его “посадить”. Нужно играть по правилам поисковой выдачи, потому что бодаться с ней — себе дороже. Отсюда вывод — внимательно проверяйте посадочные под свои запросы. Ориентируйтесь на ТОП… в этом нам помогут онлайн-сервисы, но об этом мы поговорим чуть позже. - Не гоняйтесь за НЧ-запросами.
Да, низкочастотный хвост важен, но не следует усердствовать, собирая все возможные низкочастотники для страницы. Я, например, делаю следующим образом — если в кластере собирается в районе 10-30 ВЧ-СЧ запросов, то далее для него беру только НЧ с общей частотностью не ниже 5. Хотя многое, конечно, зависит от тематики. В узкоспециализированных областях, где СЯ в принципе трудно собрать (например, какая-нибудь техника для аэродромов), есть смысл рассматривать любой ключ, т.к. каждый запрос в топе, даже НЧ, будет важен. - При сборе семантики учитывайте сезонность запросов.
Хороший пример — туристические сайты. Сезон большинства таких ресурсов выпадает на май-сентябрь. Соответственно, если вы решили собрать семантику в декабре, вы получите неточные данные — запросы с низкой частотностью, которые вы не возьмете в работу, хотя в сезон их частотность увеличивается в сотни раз. - Анализируйте не только общую частотность запроса, но и частотность его прямого вхождения.
Это поможет определить приоритетные для оптимизации страницы ключи. Для определения частотности прямого вхождения ключа, используйте оператор “!”. Пример — запрос “ехать в турцию” (без кавычек — это тоже оператор) имеет по РБ общую частотность 326, а запрос “!ехать в турцию” в том же регионе — 0. Отсюда делаем вывод — никто не использует запрос “ехать в турцию” в прямом вхождении и скорее использует другие его словоформы. Это не значит, что такой ключ не надо брать в семантику, просто с ним нужно быть внимательнее, когда начнете оптимизировать посадочную под запросы.
Ну вот из большего все, теперь поговорим про онлайн-сервисы и инструменты для сбора СЯ.
Инструменты и онлайн-сервисы для сбора семантики
Yandex.Wordstat
Онлайн-база ключевых слов от Яндекса. Источник 90% ваших запросов (для РУ-региона). Вордстат очень прост в использовании — вам нужно указать регион, по которому вы будете снимать частотность запросов, написать, собственно, исходный запрос и… все — вам предложат все связанные с исходником ключи, нужно только выбрать подходящие.
Также в Вордстате можно посмотреть сезонность запросов. Для этого выберите опцию “История запросов” и анализируйте динамику запроса за последние 12 месяцев.
Пара советов по поводу работы с YWS
Совет номер раз: так бывает, что защитная система Яндекса в какой-то момент начинает считать вас спам-ботом и на каждое действие в Яндекс.Вордстат (вплоть до перехода по страницам пагинации) требует введения капчи, от которой в районе таза разгорается пламя такой интенсивности, что при желании можно прожечь себе путь до Китая.
Чтобы предупредить незапланированное воспламенение, предлагаю для сбора семантики пользоваться браузером Opera — у него есть одна примечательная функция, которая раз и навсегда решает проблему капчи от Яндекса, а именно — встроенный VPN (подмена IP). Включить его — как два байта переслать. Для этого следуйте по пути “Меню” — “Настройки” — “Дополнительно” — “Возможности” — “Включить VPN”.
Совет номер два: для упрощения сбора нужных ключей, установите плагин Yandex Wordstat Assistant — он немного преобразует Вордстат и позволит без лишних усилий отмечать нужные ключи и копировать их целыми группами. Без него все сложнее — каждый ключ нужно вручную выделять, копировать и переносить в отдельный файл. В общем очень удобное приложение, которое экономит кучу времени вебмастера.
KeyCollector
Многим известная и очень удобная программа для парсинга Yandex.Wordstat и других семантических баз. Вот вам сразу линк на официальную страничку KC. Программа платная, кряков для нее не существует, зато есть бесплатный аналог с урезанным функционалом — это Слово*Б (я его называю “СловоЛюб” — зацензуренная версия, так сказать).
С помощью KeyCollector можно в режиме реального времени спарсить базу запросов по нужным ключевым словам, собрать для них частотности, фильтровать и удалять ключи, группировать их в кластеры, посмотреть список страниц-конкурентов в ТОП-10 по определенным ключам и многое другое. Все функции программы перечислять слишком долго — это тема на отдельную статью.
Pixelplus
Платный онлайн-сервис, который собрал в себе очень много полезного для анализа семантики и оптимизации страниц сайта. Сразу линк на сервис.
Так, если сейчас мы говорим о семантическом ядре, нам интересны следующие инструменты:
- Список URL в ТОП — позволяет проанализировать конкурентную выдачу запроса и определить, к какой посадочной странице лучше привязать ключ.
- Оценка интента запроса — тут мы можем узнать, чего ожидает пользователь, вводя тот или иной запрос. Выгоднее анализировать целый кластер, благо для этого есть возможность. Сервис предлагает нам следующие интенты: коммерция, отзывы, фото и видео, словари, музыка, путешествия. Прогнав кластер и поняв его интент, вы сможете лучше понимать, чего ожидает рядовой потребитель от вашей посадочной страницы, на которую ведут запросы из анализируемой группы, и подходят ли в принципе отдельные запросы для страницы.
- Детальный анализ запроса — в принципе полный анализ запроса по ряду критериев.
В анализе учитывается:
Геозависимость — зависит ли результат выдачи по запросу от региона пользователя.
Степень локализации — процент сайтов в ТОП-50 с ярко выраженной геозависимостью.
Слова из подсветки — слова, которые подсвечиваются в поисковой выдаче. Хороший помощник для оптимизации мета Title и Description.
Cлова СПЕКТРа — дополнительный список подсвеченных слов, выбранных по технологии СПЕКТР.
Слова, задающие тематику — слова, которые часто встречаются в сниппетах конкурентов (кроме синонимов анализируемого запроса). Также используется для оптимизации метатегов и текста страницы.
Общая и точная частоты — частотности запроса без операторов и с оператором “!”. Зачем оно надо? Вспоминаем мои советы по сбору семантического ядра (подсказываю — пункт 5).
Число главных страниц в ТОП — помощь при определении посадочной страницы.
Наличие витального ответа — показывает является ли анализируемый запрос брендовым.
Число найденных результатов — показывает сколько всего было найдено документов (читай — страниц), соответствующих запросу.
Бюджет по MegaIndex — показывает уровень конкуренции в Яндексе. Чем выше число, тем конкурентнее запрос.
Число объявлений в Яндекс.Директ — кол-во платной рекламы по запросу.
Число точных вхождений в Title и сниппеты из ТОП-50 — оцениваем корректность ключевой фразы, т.е. как часто она используется в прямом вхождении в сниппете.
Средний возраст документов — особенно актуально для молодых сайтов. Чем старше страница конкурента, тем тяжелее ее победить.
- Поисковые подсказки для Яндекса и Google — хорошее подспорье, когда нужно разнообразить кластер актуальными запросами, либо просто составить грамотное и всеобъемлющее техническое задание для копирайтера. Поисковые подсказки подскажут (Вова может в копирайт, не забываем!) вам какие ключи вы не учли при составлении семантики и чем обычно интересуются пользователи, вводя запрос.
- Вместе с запросом ищут — сбор синонимичных запросов. Если быть точнее, сбор запросов, которыми интересуются, наравне с анализируемыми запросами. Опять же помогает расширить как отдельный кластер, так и семантику проекта в целом (помним совет номер 1 про коммерческие и инфозапросы).
Семантика в Google
Единственное, что я упустил еще в самом начале статьи, — это сбор семантики с частотностями в Google. К сожалению, данный поисковик не предлагает таких сервисов, как Яндекс.Вордстат, и частотности запросов можно узнать лишь через Google Adwords на этапе настройки рекламной кампании. Также можно воспользоваться платными онлайн-сервисами SemRush или SerpStat, которые позволяют анализировать поисковые запросы с учетом частотностей Google. Помните, что в Google частотности округляются до десятков. Т.е. запрос с частотностью 10 может на самом деле иметь частоту от 10 до 19.
Вывод
Семантическое ядро — это, наверное, один из важнейших отправных пунктов в оптимизации вашего сайта, поэтому подойти к сбору семантики нужно ответственно, “с головой”. От этого будет зависеть не только итоговый анализ ваших достижений, но и изначально грамотная оптимизация посадочных страниц.
Что же, я надеюсь, моя статья поможет вам грамотно собрать СЯ и двигать свой сайт в светлое коммунистическое будущее. А у меня на сегодня все, на часах 3:38 и я иду спать. Вам желаю всего хорошего, подписывайтесь на наш блог, чтобы не пропустить интересные статьи от меня и моих коллег… ну и не забывайте чистить кэш перед сном.
__________________________________
Автор — Владимир Еленский Практикующий SEO-специалист MAXI.BY media. Опыт работы более 5-ти лет. Хороший человек и просто красавчик. _________________________________________
Digital агентство MAXI.BY media
Источник
Пожалуй, самое большое заблуждение — считать, что для сбора семантического ядра существует волшебная кнопка. Чтобы получить стартовый список фраз, нужно провести серьезную работу по поиску синонимов и анализу конкурентов. Часто базовые списки формируются в результате «мозговых штурмов». Что касается сервисов для сбора поисковых фраз, то использовать их стоит и на первом этапе, и в дальнейшем — для регулярного расширения семантического ядра.
О том, какие инструменты важны для сбора семантики, поговорим в этом материале рубрики «Азбука SEO».
Яндекс.Вордстат
Позволяет собирать семантику в широком, фразовом и точном соответствии.
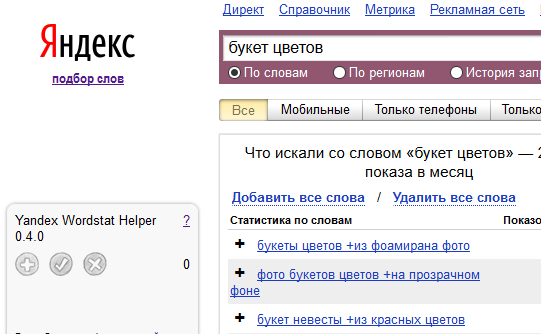
В широком соответствии Вордстат найдет все фразы, которые так или иначе относятся к фразе в поиске.
В фразовом соответствии — все запросы с фразой в поиске и ее склонениями.
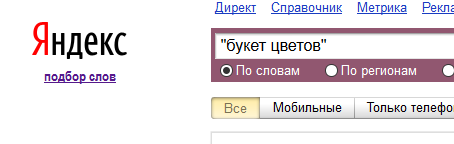
Если искать в точном соответствии, появятся только те запросы, которые содержат фразу из поиска, в том же падеже.
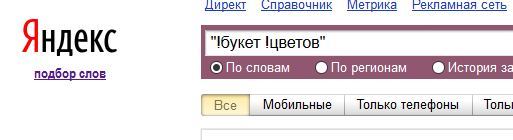
Очень удобно использовать сервис в связке с программой Key Collector, с помощью которой легко выгружать данные из Яндекс.Вордстат в широком соответствии вместе с данными о частотности.

Планировщик ключевых слов Google
Инструмент подходит как для русскоязычного сегмента, так и для любых регионов, в которых работает Google Реклама.
Для начала работы нужно кликнуть в верхней панели Google Рекламы на раздел «Инструменты» и выбрать параметр «Планировщик ключевых слов».
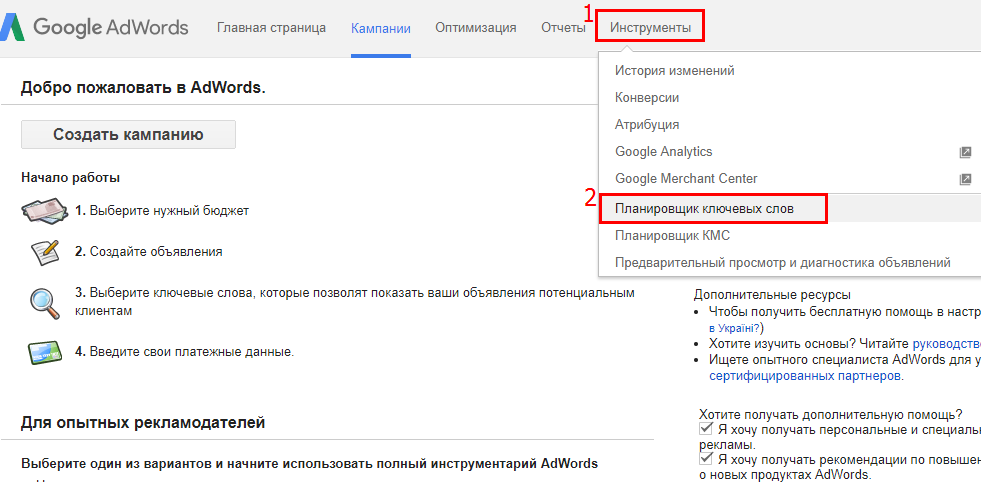
Откроется меню выбора опций, в котором нужно перейти на вкладку «Поиск новых ключевых слов по фразе, сайту или категории»:
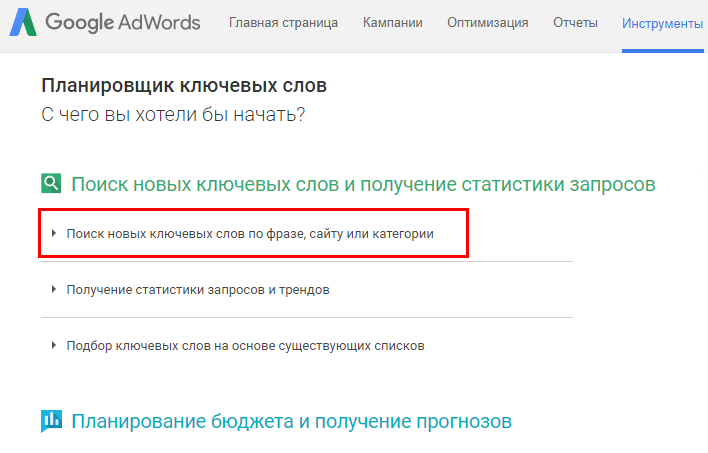
В данном разделе можно настраивать такие параметры:
- ключевую фразу, по которой будет осуществляться поиск;
- тематическую категорию товара;
- регион, в рамках которого нужны поисковые запросы;
- язык поисковых запросов;
- систему поиска запросов;
- минус-слова, которые не должны содержаться в словосочетаниях с ключевыми.
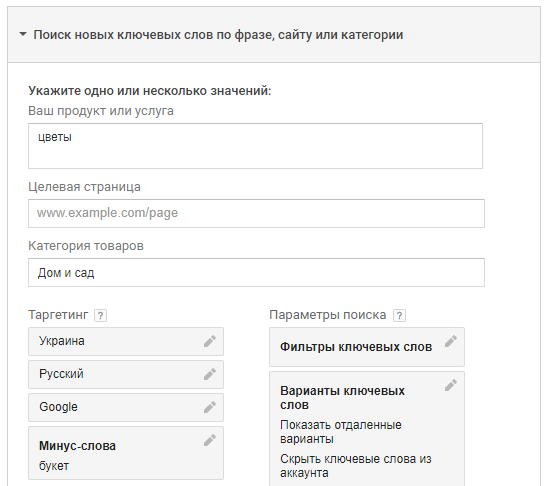
После настройки данных параметров следует нажать кнопку «Получить варианты», и сервис предоставит варианты ключевых слов, которые могут быть также синонимами исходного ключа.
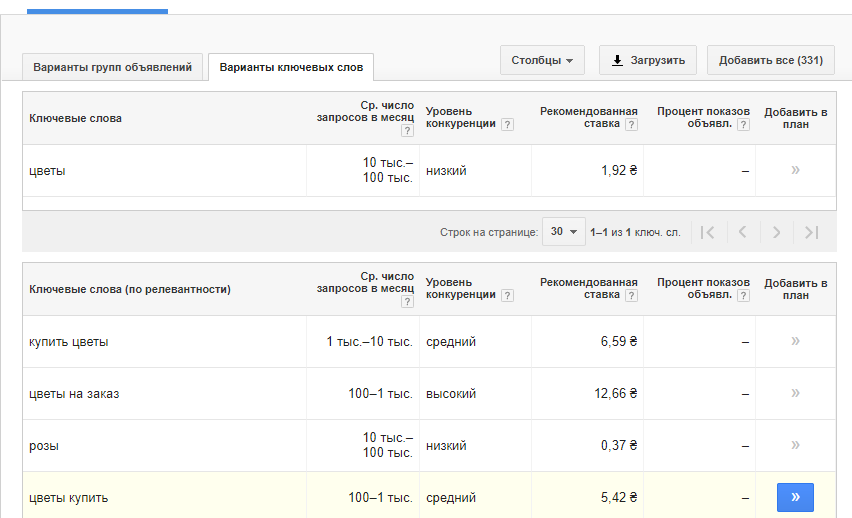
Информацию можно выгружать в CSV и таблицы Google.
Сильные стороны сервиса:
- подбор синонимичных фраз;
- возможность задавать списки минус-слов;
- объемная база поисковых запросов от Google.
Один из главных недостатков бесплатного аккаунта — неточная частотность, которую Google отдает диапазонами от 10 тысяч до 100 тысяч, от 100 тысяч до 1 тысячи, и так далее. Ориентироваться на такие частотности при продвижении нельзя, поэтому приходится либо перепробивать среднее число запросов в месяц в платном аккаунте, либо использовать другие сервисы.
Истории бизнеса и полезные фишки
Serpstat
Комплексная SEO-платформа для сбора поисковых фраз по ключевым фразам и доменам сайтов. Количество баз регионов постоянно увеличивается, а инструментарий не сводится только к расширению семантики.
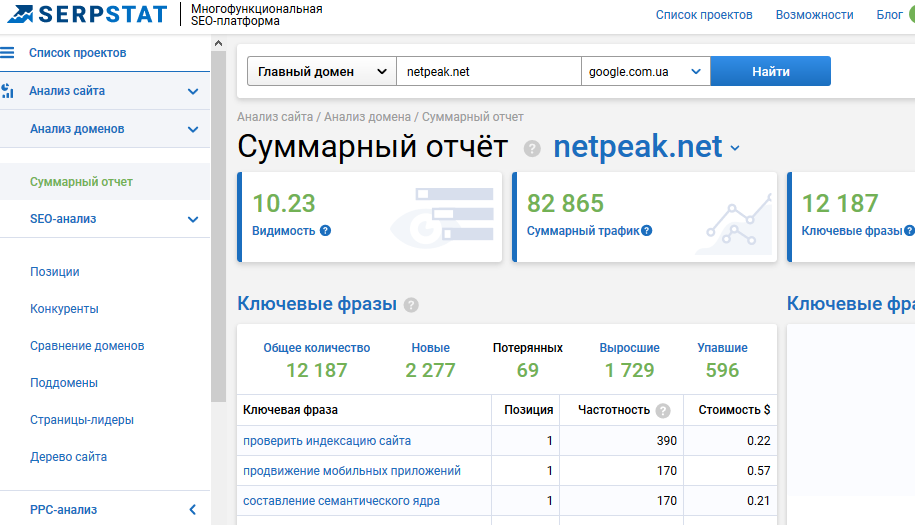
С помощью Serpstat можно определить конкурентов сайта, узнать ключевые слова, по которым их можно найти в поиске, и выгрузить этот список для использования в собственной семантике.
Достоинства сервиса:
- разнообразный инструментарий;
- удобные отчеты, включающие частотность фразы по конкретному региону;
- возможность выгружать ключевые слова для отдельной страницы сайта.
Недостатки:
- база сервиса постоянно обновляется и дополняется, но между ее апдейтами нельзя гарантировать точность частот запросов;
- данные по некоторым низкочастотным запросам могут отсутствовать;
- сервис пока работает с ограниченным количеством стран и языков.
Key Collector
Программа для сбора, расширения, чистки и кластеризации семантического ядра. Поможет быстро собрать фразы из всех описанных выше сервисов, сделать срез частотности для нужных регионов и обработать семантику.
Сервис достает фразы по стартовым спискам, очень удобен для работы с базами в любых форматах.
С помощью Key Collector легко вытянуть частотность фраз по Serpstat, Yandex Wordstat и выгруженных из других сервисов списков.
Semrush
Бесплатная версия сервиса предоставляет по 10 фраз в широком и фразовом соответствии, с частотами и под нужный регион.
Также сервис предлагает посмотреть поисковые фразы по заданному ключевому слову в других регионах, это позволяет расширить спектр поисковых фраз.
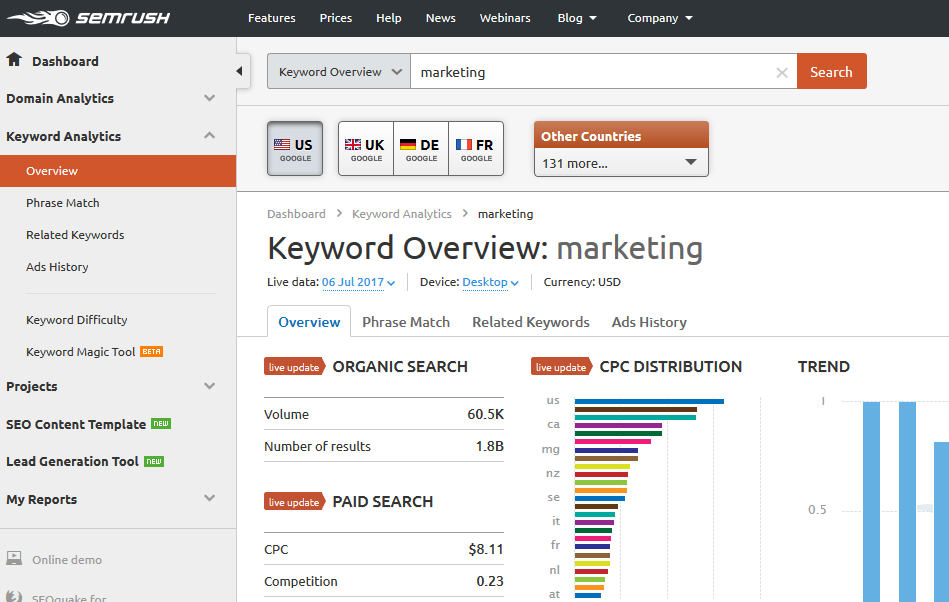
Недостатки:
- в бесплатной версии нельзя увидеть больше 10 фраз;
- цена платной версии 100$;
- нельзя загружать ключевые фразы списком.
Достоинства:
- охватывает все страны мира, удобно собирать запросы и частотность под западный регион;
- по каждому запросу показывает топ сайтов в выдаче, на которые можно ориентироваться для сбора базовых списков поисковых запросов.
Keywordtool
Сервис собирает семантику для зарубежных сайтов в широком соответствии. Отдельно можно подбирать поисковые подсказки и фразы, в которые включено базовое ключевое слово. В одной сессии бесплатной версии сервис отдает до 1000 фраз без указания частотности.
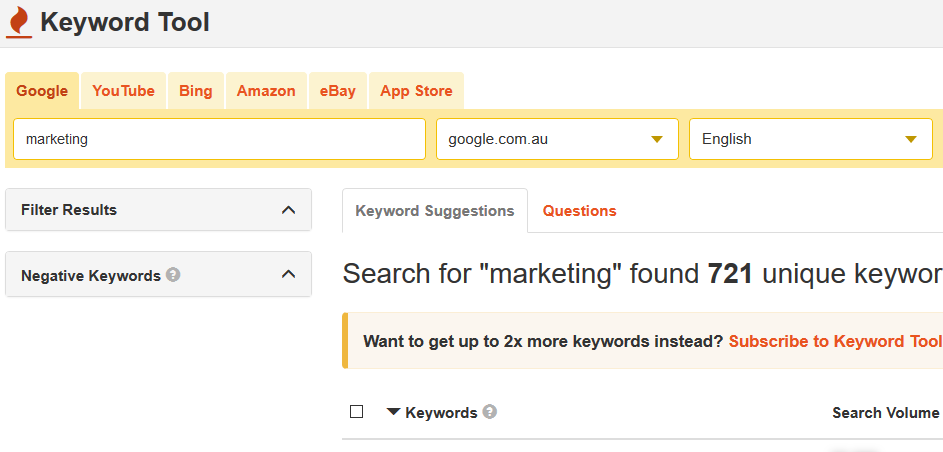
Достоинства:
- широкая география подбора запросов и выбор языка;
- отдает поисковые запросы из YouTube, Amazon, eBay, App Store;
- охват поисковых запросов больше, чем у Google Рекламы;
- удобное копирование списка запросов — можно перенести в любую таблицу в один клик.
Недостатки:
- не показывает частотность в бесплатной версии;
- нельзя загружать фразы для поиска списком;
- не ищет синонимы ключевого слова, а только фразы, в которые оно включено.
Ubersuggest
Сервис охватывает все основные регионы и языки мира. В бесплатной версии показывает не более 750 фраз для одного запроса.
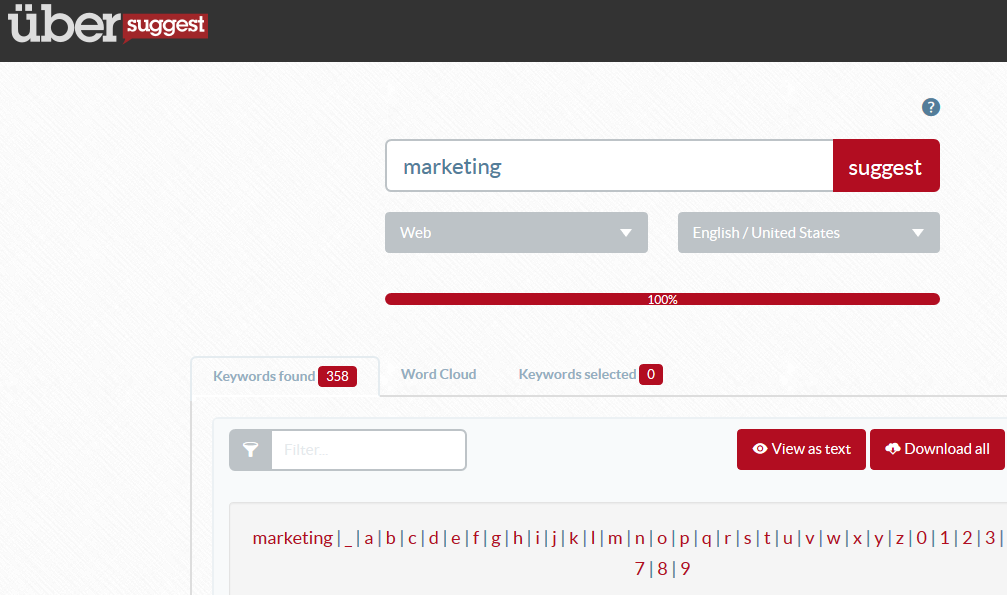
К достоинствам можно отнести то, что сервис сортирует найденные фразы по алфавиту, в соответствии с приставкой к ключевой фразе.

В результате поисковые фразы сразу делятся на группы, и с ними легче работать при дальнейшем составлении семантического ядра.
Бесплатная версия инструмента некорректно показывает частотность, нельзя найти синонимы ключевого слова.
Ahrefs Keywords Explorer
Инструмент собирает семантику в широком, фразовом и точном соответствии под нужный регион, частотность учитывается.
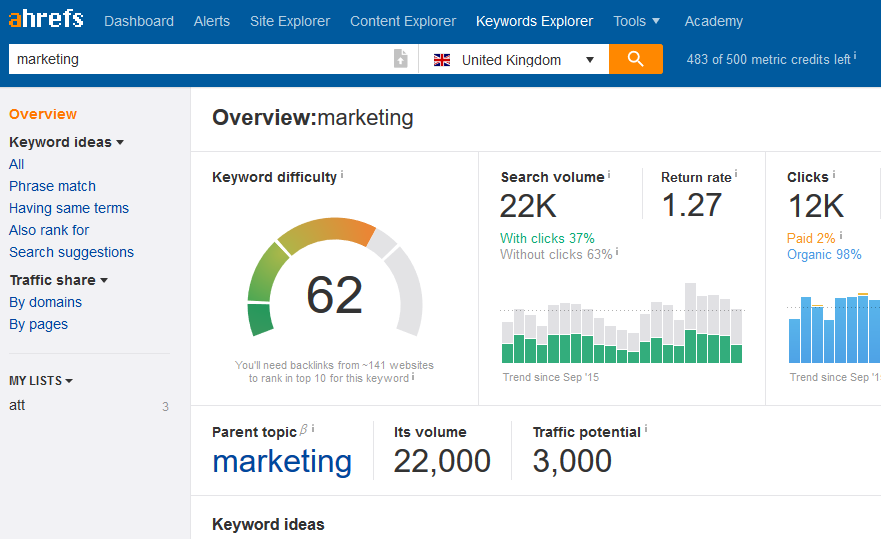
Также можно задавать параметры минус-слов, фразы с которыми не должны попадаться в сочетании с ключевыми, смотреть топ поисковой выдачи от Google по базовым ключевым фразам.
Недостатки сервиса: отсутствие бесплатной версии и зависимость от обновления баз поисковых фраз.
Выводы
Сервисы по сбору семантики предоставляют разные ключевые слова: у всех разные базы данных и источники информации. Чем больше инструментов задействуется, тем полнее картина.
Но если вы выбираете качественный сервис для расширения семантического ядра, обращайте внимание на такие характеристики:
- размер базы поисковых запросов и частота ее обновления;
- выбор источника поисковых запросов (Google, Yandex, Bing);
- показ актуальных частотностей ключевых слов;
- возможность подбора синонимов для ключевых фраз в отдельном отчете;
- присутствие загрузки поисковых фраз для расширения списком, а не по одному слову;
- доступность баз поисковых фраз на всех языках и для всех стран мира;
- возможность искать поисковые подсказки для ключевых фраз;
- возможность добавлять список минус-слов в конкретной тематике.
После первого сбора ключевых фраз стоит еще раз пересмотреть высокочастотные, среднечастотные запросы, собрать список из частотных запросов, которых не было в базовом списке, и повторно выгрузить по ним семантику повторно.
Как составить и расширить семантическое ядро на примере сайта в тематике «защита от бытовых вредителей» — читайте в статье Александра Шараевского.
Источник